AI Software Development Services: What It Takes to Ship a Real Product
 Melissa AshfordCOO
Melissa AshfordCOO
Most teams searching for AI software development services don't actually need "AI." They need a working product that happens to use a model somewhere inside it. That sounds pedantic until you've watched a six-figure budget vanish into a demo that wowed a boardroom and then fell over the first week real users touched it.
We build AI products at Lomray. We've shipped the unglamorous version of this — the part after the proof-of-concept, where the model is maybe 15% of the job and ordinary software engineering is the rest. Here's what that work involves, and where it tends to break.
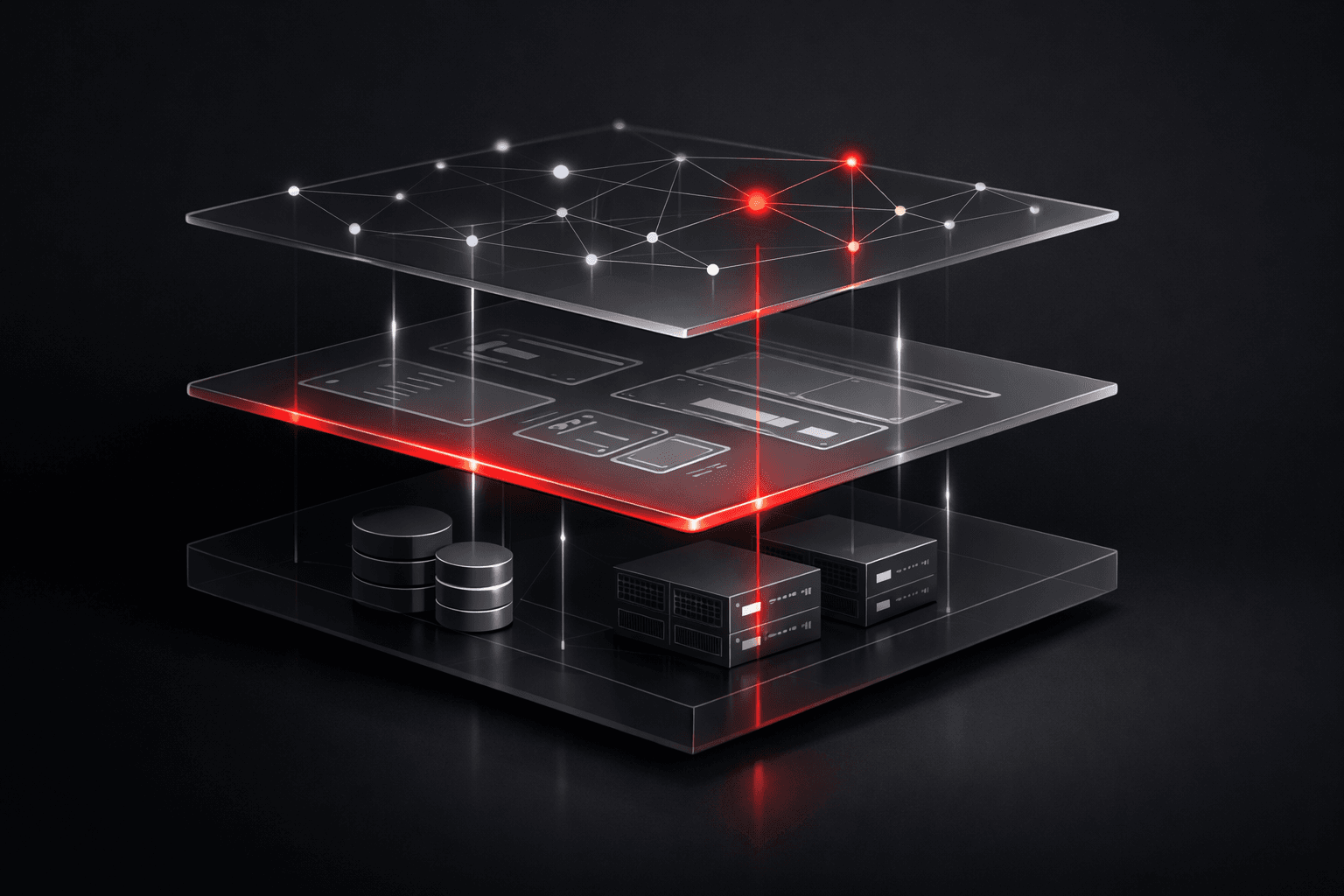
What "AI software development services" really covers
The phrase gets stretched to mean everything from a weekend ChatGPT wrapper to a custom-trained vision model. A serious build has three layers, and the gap between teams is usually how many of them they actually handle.
First, the model layer: choosing the right model — often an existing one, fine-tuned or prompted rather than trained from scratch — plus the retrieval and context plumbing that feeds it good inputs. Then the product layer, which is the real app around it: auth, billing, the interface people touch, the moderation that keeps it safe, the analytics that tell you whether any of it works. And underneath both, the infrastructure layer — what happens when traffic is a hundred times your demo. Caching and rate limits, plus a fallback for when your model provider has an outage at 2am.
A team that only does the first layer hands you a notebook and an invoice. A team that does all three hands you something users can pay for.
Where AI projects quietly fail
Three patterns show up again and again.
The cost surprise
A demo runs on a few hundred requests and costs nothing worth noticing. Then you launch, usage climbs, and the model bill lands. On one platform we inherited, inference was running close to $40k a month — more than the rest of the company's hosting combined — because every request hit the most expensive model with no caching and no cheaper tier in front of it. We cut it by more than half in two weeks without users noticing a thing. Cost engineering isn't a nice-to-have here. It's the line between a real margin and a slow bleed.
The reliability gap
Models are non-deterministic, and the providers go down. If your product treats a model call like a normal database read — always returns and always makes sense — your users will find the edges within hours. Production AI needs timeouts, retries, graceful degradation, and a clear plan for when the output is simply wrong.
The "it's just a prompt" trap
A clever prompt buys a great first impression. Holding that quality steady across thousands of messy real-world inputs is a different and much harder problem. That's evaluation and guardrail work — the boring, essential part the demo never reveals you'll need.
How we approach an AI build
We start by separating the part that's genuinely AI from the part that's ordinary software engineering — which is almost always the bigger part. The model gets chosen for the job, not for the press release. Then we build around it the way we'd build any product that has to survive real users.
In practice that comes down to a few habits. We design for scale on day one, because we've run conversational AI at the volume where millions of messages move through per day, and the cost and queueing decisions you defer there get expensive fast. We ship web and mobile from a shared React and React Native core, so the AI behaves identically everywhere and you don't fund the same feature twice. And we test against the inputs that break a feature before we call it done, not the ones that flatter it.

A concrete example
One product we've engineered is a consumer AI companion platform — open-ended conversational characters that millions of people use every day. The model was never the interesting part; plenty of teams can call an LLM. The job was keeping latency low and cost sane at that traffic, while moderation ran at scale and the experience held consistent across web and mobile as usage climbed month over month. That is what AI software development services actually means in production: making the clever part survive the brutal, boring reality of scale.
In-house, or a partner?
If AI is your core product and you're building a permanent team around it, hire in-house. Long-term, nothing else beats it.
A partner earns its place in a few situations: when you need to move now and can't wait on a hiring cycle, when you want engineers who've already hit the cost and scaling walls so you don't pay tuition learning them, or when AI is one important feature of a larger product rather than the whole company. The wrong reason to outsource is "we don't get AI and want someone to figure it out for us." A good partner leaves you more capable. They don't hold the knowledge hostage.
Start with the problem, not the model
The best AI projects we've shipped began with a clear problem and a number attached — cut support load by a third, lift trial conversion by ten points — never with "we should add AI." Name the problem first. The model is just one tool we'll reach for, or skip.
If you're weighing an AI build and want a straight answer on what it'll really take — scope, cost, and the parts most quotes leave out — book a call with our team. We'll tell you if you need us. We'll also tell you if you don't.